The Modern Data Engineer Part 5: Governance Automation, Not Governance Theater
Governance only scales when metadata is produced by delivery workflows, not manual stewardship.
The Modern Data Engineer Part 5: Governance Automation, Not Governance Theater
In Part 4A and Part 4B, I argued that the Silver semantic boundary is where trust is won or lost, and that governance must be connected to delivery.
This part is about what governance is actually for, and why most programs fail to deliver it.
Before going further: the approach described here assumes observable pipelines, stable schemas, and some form of lineage tracking. Many teams are still building that foundation, and there is no shame in that, but it does mean some of what follows will be aspirational rather than immediately actionable.
1. The Anchor Question
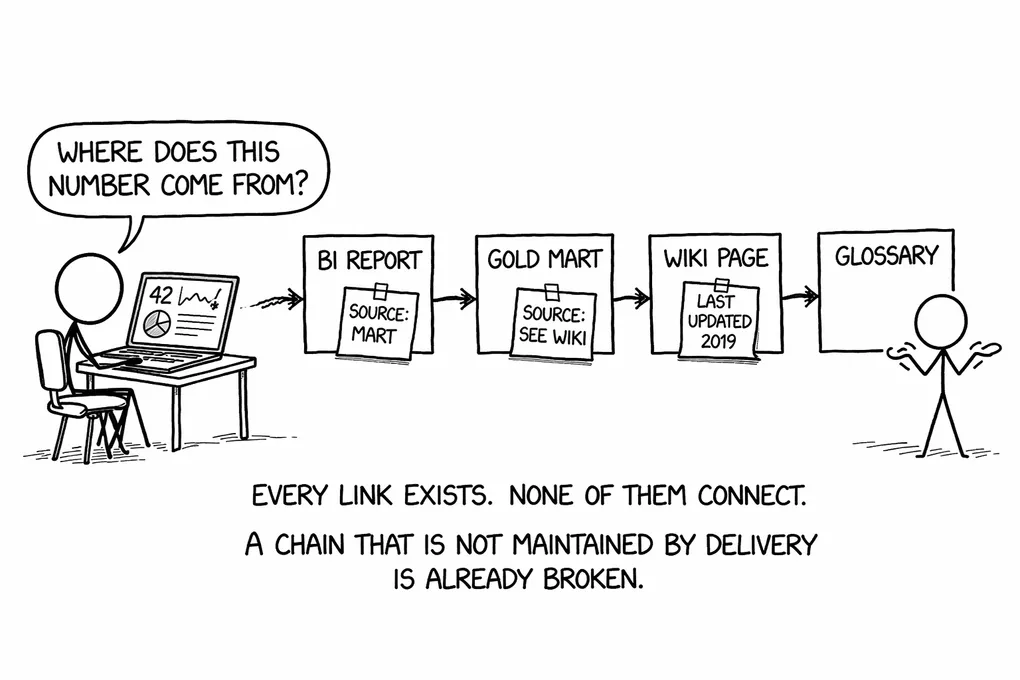
Can you trace any number in a report back to a business definition, and know exactly what breaks when that definition changes?
Most teams cannot. Not because they lack tools or talented people, but because the chain that would make that answer possible was never built. The number exists in a dashboard. The definition exists in a glossary. The model that connects them was written by someone who has since moved to another team, and nobody has updated the documentation since the first sprint ended.
That is the actual governance problem. Everything else, the catalog implementations, the stewardship meeting cadences, the data ownership fields that nobody fills in correctly, is downstream of it. Teams call all of that governance. What governance actually needs to deliver is something more specific: traceability and change confidence. The ability to say, with certainty, what a number means and what will break when that meaning evolves.
2. The Traceability Chain
When it works, the chain has four links. A business definition lives in a glossary, stated precisely enough to be implemented. That definition is materialized in a Silver Conformed Entity that encodes the logic once in a tested, versioned artifact. That model feeds into a Gold mart, which is a consumption optimization layer: it aggregates and shapes the data for specific analytical use cases, but does not redefine the metrics the Conformed Entity already committed to. Gold then carries those metrics into one or more BI reports and dashboards. Each link is a contract, and each contract depends on the ones before it.
Take something like “active customer.” The glossary entry defines what active means in terms the business agrees on: a customer with at least one completed order in the past 90 days, excluding trial accounts. A Conformed Entity implements that logic and nothing else; it does not reinterpret it per mart. Gold consumes the entity and aggregates across dimensions. Three dashboards consume that mart. When the business decides that 90 days should become 60, you change the definition in one place, update the model, run the tests, and know which dashboards will show different numbers before anyone opens them. That is what the chain enables.
It also answers a question that currently triggers expensive, demoralizing investigations in most platforms: where does this number come from? When that question arrives in a Slack message at 4 PM before a board meeting, the answer should be a lineage traversal, not a phone call to whoever happened to build the report.
3. Why the Chain Breaks
Each link in the chain typically lives in a different tool, and those tools have no native contract with each other. Business definitions sit in Collibra, or a Confluence page, or a shared spreadsheet that someone started in 2021 and nobody owns. Models live in dbt. Lineage gets captured somewhere in the warehouse or a catalog, depending on what the team has set up. dbt Catalog does provide consumer-accessible lineage with column-level detail, but that is reserved for dbt Cloud Enterprise plans. Reports live in Power BI or Tableau, with their own internal metric definitions that may or may not match what the model says.
When delivery happens under pressure, the model changes. The glossary does not automatically reflect it. The catalog does not automatically update. The BI impact is unknown until someone investigates after the fact. That investigation is expensive and demoralizing precisely because it was avoidable. The definition and the implementation were once aligned. At some point they drifted, silently, because nothing required them to stay connected.
Manual governance is a bet that documentation will keep pace with delivery. Under real pressure, it cannot. The definition of “active customer” in the glossary says 90 days. The model says 60 days because someone updated the logic six months ago after a product decision and forgot to update the wiki. Two dashboards now disagree on the same metric. When that surfaces in a leadership meeting, the cost is not just the time to investigate. The trust that the platform is telling the truth takes a real hit.
This is governance theater: the appearance of control without the substance of it. The fields are filled in. The owners are assigned. The catalog looks complete. But the chain is broken, and nobody knows it until something goes wrong.
A chain that is not maintained by delivery is already broken.
4. What It Enables When It Works
Before getting into automation mechanics, it is worth being concrete about what a working chain actually changes, because the practical benefits are more immediate than teams expect when they first approach this as an architecture problem.
Change confidence is the most significant one. If you know the full downstream impact of a definition change before you make it, you can make changes safely and at pace rather than freezing because you are afraid of what you might break. Teams on platforms without traceability often develop an informal rule of never touching shared models unless absolutely necessary, because the blast radius is unknown. That risk aversion compounds over time into a platform that is slow to change and increasingly out of step with business reality.
Investigation speed changes as well. When two reports disagree, the current path in most organizations routes through several people across two or three days. With a working chain, it is a lineage traversal and a diff. The answer is usually visible within an hour, and it points directly to where the divergence was introduced.
Real ownership becomes possible when the accountability is wired to something that actually changes. An owner who is automatically alerted when upstream models change, or when test results on a model they own start failing, can act before consumers notice. An owner assigned in a spreadsheet with no operational hook is a name, not a responsibility.
Onboarding improves as a side effect. A new team member who can trace a metric from a report back through a Gold mart to a Conformed Entity to a glossary definition does not need to spend months asking questions the last person also had to ask. That institutional knowledge is in the platform, not in the head of whoever happened to be there at the start.
5. Automating the Plumbing
The chain is difficult to build manually and practically impossible to maintain manually at the pace most delivery teams move. Automation is not primarily an efficiency story here. It is the mechanism that keeps the chain current when delivery is happening every week.
What to automate is well-defined once you accept that premise. Metadata must sync from dbt to your catalog on merge: descriptions, owners, tags, and test results. Lineage ingestion must be continuous, not a quarterly catalog refresh. When an upstream schema changes, impact analysis must run automatically and route to the relevant model owners before anything breaks downstream. Governance policy checks belong in CI and must be blocking — a model without a declared owner or missing key integrity tests should not reach production. Strengholt makes the same argument in Data Management at Scale [1]: metadata collection, discovery, and maintenance should be automated as a core part of the architecture, not treated as a separate operational concern.
The pattern that makes this practical is treating governance metadata as a byproduct of delivery, not as a parallel artifact that someone has to maintain separately. When a new Conformed Entity is added to the platform, CI verifies key integrity and test coverage before merge. The catalog updates on merge, reflecting the new model’s documentation, owner, and lineage position. Impact alerts route to the model owner when something upstream changes. Data stewards only get involved when there is an actual semantic dispute to resolve, not as the default mechanism for keeping documentation current.
The metric that tells you whether this is working: what percentage of your critical metric layer is fully traceable? All four links present and current: a live business definition, a tested model that implements it, lineage from that model forward to marts and dashboards, and an active owner who is reachable and notified when things change. Most teams, when they measure this honestly, find the number lower than they expected.
6. The Human Layer
What stays human is the part that actually requires judgment. Deciding what a KPI means. Resolving definition conflicts when two domains use the same term differently. Approving changes that have a large downstream blast radius and need deliberate coordination rather than automated propagation.
The human layer is where BI specialists and data stewards need to work in the same direction, and that only happens when the chain gives them something to work from. The roles are distinct: BI specialists own implementation correctness of the semantic layer, the data steward owns definition integrity, and data engineers own the ingestion and pipeline reliability underneath it. When those boundaries are clear, problems route to the right person instead of bouncing between teams.
What matters is not what the role is called but that ownership exists per layer. Every layer needs a named owner accountable for its correctness. Without that, inclusive role definitions become a polite way of saying nobody is responsible.
A BI specialist who notices a metric behaving unexpectedly should not have to track down whoever built the mart. The lineage tells them which model to look at and who owns it. If the definition in the glossary no longer matches what the model implements, that is a signal for the steward, not a debugging task for the BI specialist. The steward surfaces the conflict, determines whether the model changed without a definition update or whether the definition needs to evolve, and routes it to the right owner for resolution. What the steward should not be doing is manually refreshing catalog entries after every pipeline deploy or chasing teams to fill in ownership fields. Automation handles that. The steward handles meaning.
The same logic applies when a BI specialist changes a Conformed Entity that other BI consumers depend on. That change should be communicated intentionally: what changed, why, and which reports will show different numbers. Not as a Slack message that gets buried, but as a governed handoff: a versioned change with a clear owner, visible in the same lineage graph other BI specialists use to understand their reports. When that handoff is structured, consuming BI specialists can plan around it. When it is not, they discover it in production and the investigation starts again from scratch.
The interaction also runs the other way. The steward is not only a reactive arbitrator; they are a proactive partner to the BI layer. Before approving a definition change, the steward needs to understand what it will break in practice, and that means asking the BI specialists who consume it, not just reading the lineage graph. Before a definition evolves in the glossary, the steward should be checking with the people who implement it whether the current wording is actually workable.
Implementing a definition in a Conformed Entity is how a glossary entry gets tested against reality. And this matters more than you may think. A definition that reads clearly in a wiki often turns out to be underspecified the moment someone tries to write the SQL: which order types count, which timezone applies, how to handle accounts that span both sides of an edge case. This is not a failure of prior coordination, it is just what implementation does to language. The precision the business needs in order to govern a metric is often only achievable through contact with the implementation. That means the BI specialist is not a passive consumer of definitions handed down from stewardship. They are the person whose work forces the definition to become more exact than it was. When they hit an ambiguity, the right move is to route it back to the steward to resolve in the glossary, not to paper over it with a local assumption that quietly becomes the de facto definition for every downstream report. The steward’s job in that moment is to take the question back to the business, get an answer that actually handles the edge case, and return a definition that the implementation can commit to. Run that loop enough times and the glossary starts to reflect how the business actually works, not just how it describes itself in meetings.
7. Tooling Is Not the Problem
Enterprise catalogs like Collibra, Purview, and Alation can support this architecture. So can open-source options like DataHub and OpenMetadata. Cloud-native options exist as well. None of them build the chain for you.
Databricks Unity Catalog already delivers native column-level lineage in production, captured automatically from Spark execution plans without any additional instrumentation. BigQuery with Dataplex offers similar capabilities. That structurally closes part of the gap for teams consolidated on Databricks. Microsoft Fabric is heading in the same direction: item-level lineage is native, but column-level lineage for Spark workloads still requires OpenLineage instrumentation and is not automatic out of the box as of early 2026. In heterogeneous environments with multiple warehouses, BI tools, and catalog systems, the gap still has to be bridged through integration work rather than platform defaults.
The question is not which tool to choose. The question is whether you can trace a business definition to a report, end to end, today. If the answer is no, the constraint is not the tool. It is that the chain was never built, and picking a new catalog does not build it for you.
The Takeaway
Governance is not a documentation project. It is not about filling in fields in a catalog, assigning nominal owners, or maintaining a glossary that nobody links to anything. It is also not about purchasing an enterprise data catalog and declaring the platform’governed’. What it actually is, is about whether the chain from business definition to report exists, and whether it stays current as delivery happens around it.
The failure mode most governance programs fall into is inverting the effort: human energy spent on documentation mechanics, while the semantic decisions that actually matter, what a number means, who can change it, what breaks when it changes, get made informally, inconsistently, or not at all. The result is a platform that looks governed and is not.
Automate the plumbing: metadata sync, lineage ingestion, impact analysis, policy checks in CI. Reserve human judgment for what a number means, who owns it, and what happens when it changes. That division is how the chain stays intact as delivery keeps moving, and a chain that stays intact is the only governance that actually works.
References
[1] P. Strengholt, Data Management at Scale, 2nd ed. Sebastopol, CA, USA: O’Reilly Media, 2023. [Online]. Available: https://www.oreilly.com/library/view/data-management-at/9781098138851/
Join the Discussion
Thought this was interesting? I'd love to hear your perspective on LinkedIn.