Odido still had my data
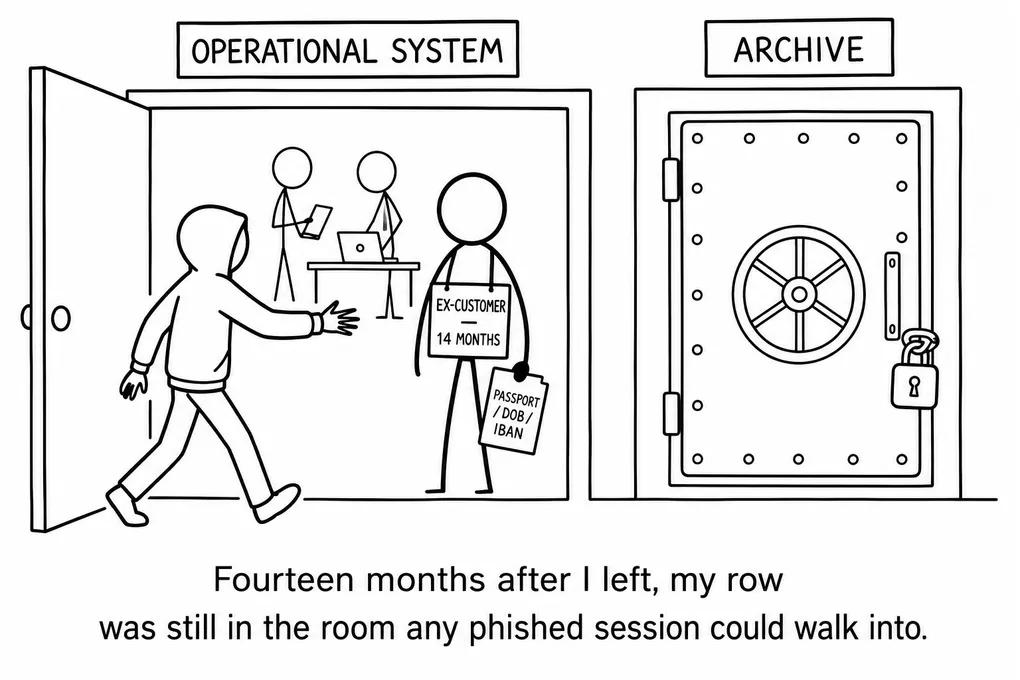
Fourteen months after my Ben contract ended, the customer service system that held my passport number was breached. Five architectural decisions in that system shaped how the incident landed, and each is a pattern data professionals already follow.
Odido still had my data
1. The fact, dated
I was a Ben customer for five years. From December 2019 to December 2024 my mobile subscription ran through Ben, the budget brand owned by what was then T-Mobile Netherlands and is now called Odido. At signup I had given them the usual things: name, address, phone number, date of birth, IBAN, and the number and validity dates of my passport and driver’s license. In December 2024 the contract ended and I switched providers.
On 12 February 2026, fourteen months after my contract ended, an email arrived from Ben. It was signed by Søren Abildgaard, CEO of Odido. He wrote that Ben had been hit by a cyberattack and that my data was probably part of what had been taken. The email listed the fields the attackers had pulled: name, customer number, address, phone number, date of birth, passport number and validity, driver’s license number and validity. The branding throughout was Ben. The email was written to me as if I were still a Ben customer. I had not been one for fourteen months.
What follows is in two parts: the chain of events as the public record describes them, and the five architectural decisions inside the customer contact system that determined what an incident like that looks like when it lands.
2. What happened
In early February 2026, customer service credentials at Odido were phished. The attackers then called the affected employees, posing as members of the ICT department, and pushed them into approving fraudulent logins and waving through MFA. From there they held an authenticated session inside Odido’s Salesforce instance, where they ran an automated scrape over several days. Six million customer records left the system before anyone inside Odido noticed. The breach was publicly announced on 12 February 2026.
That is the chain of events. The phishing call is what got the attackers in, and the call is a separate problem with its own defence. What decided everything after it, how much a single compromised session could reach and how long those records had been sitting there to be reached, was a set of architectural choices made years before anyone picked up the phone. Five of them shaped what this incident became, and the rest of this post takes them one at a time.
3. Pattern 1: Session-scoped read limits
Six million Odido customer records left the customer contact system through a single phished customer service session. The compromised session held one customer service role’s credentials and walked off with reach the role had no operational reason to hold.
Authentication is whether the right person is at the keyboard. Authorization is how much of the database that person can reach in one sitting. These are different controls with different design assumptions, and the second is what decides the blast radius when the first fails. A role whose operational job is to answer one customer at a time should not, by holding that role, be able to pull millions of rows in a few days. The session’s read scope belongs bounded to per-customer work, and bulk reach belongs behind a separate authorization with separate approval and separate logging.
Hard caps on records returned per query, rate limits per session, and a structural separation between transactional read and bulk export are the standard controls. The question is whether they are configured to fire below the level a hostile session would use to run an extraction.
The combination sensitivity of the row decides where the cap sits. A row containing name plus passport plus date of birth plus IBAN is categorically more sensitive in aggregate than any single one of those fields, and the read limit has to be designed against that combined profile rather than the field-by-field one. Part 8 of the Modern Data Engineer series is the input that decides what that profile actually looks like.
4. Pattern 2: Bulk-extraction observability
Reach bounds are the first line. Observability is the second. Even when reach is bounded correctly, there will be days when the bound was set wrong, or where an attacker walks within the bound for as long as it takes to fill the table. Multi-day undetected extraction is paid in scale, and the pattern that limits the cost is observability over what the session is actually doing.
In production this looks well-documented. Bulk data exports and API usage are audited continuously, with alerting tuned to volume, time-of-day, and burst anomalies. Login history is reviewed for unusual geographies and IPs. The operational question is whether these alerts are configured tight enough to fire while the extraction is still running, and whether they reach someone in time to act.
Sijmen Ruwhof, the security researcher who walked NOS through the Odido attack on 13 February 2026, put the scale plainly: “With this method an extraction genuinely takes several days, and the whole time it has to remain unnoticed.”
The vendor documented the controls before the breach. Salesforce’s blog post on 28 January 2026 recommended both: audit bulk data exports and API usage, and review Login History for unusual IPs or geographies. The FBI IC3 FLASH advisory naming the threat actor cluster behind this attack pattern (UNC6040 and UNC6395) went out on 12 September 2025. Both warnings name the kind of activity that ran inside Odido between those advisories and the announcement on 12 February.
The public record does not separate three possibilities: the controls were not deployed, the controls were deployed but disabled, or the controls were deployed and producing alerts that no one read. NOS asked Odido on 27 February whether the company had acted on the Salesforce or FBI warnings, and Odido did not respond. Every data professional reading this has a platform. The controls are either not there, switched off, or firing into a void. Which one is yours?
5. Pattern 3: Disclosure-ready incident response
Odido sent me a breach notification on 12 February. The per-customer email placed my email address on the “not leaked” list and did not mention IBAN. NOS’s article at 13:11 that same afternoon listed both as compromised. Same controller, same day, two incompatible accounts of which fields were taken. The per-customer letter and the press statement should come from the same query against the same data. If they don’t, the journalists fill the gap.
The same disconnect surfaced twice more. On 25 February, NOS reported a 10,000-record sample with 266 cases of sensitive customer service notes, including 128 referencing bewindvoerder, the Dutch term for formal financial guardianship. Odido told NOS it had not known the sensitive notes were in the leaked data until NOS contacted them. The customer-facing acknowledgement went up only after.
The third episode is the password_c field. The criminals’ ransom note on 24 February claimed passwords were taken. Odido’s response that day, given to NOS, was: “To identify yourself when calling Odido as a customer, some customers have a verification word.” The criminals were misreading the field. The schema name in the customer contact system is password_c. The public-facing description on Odido’s security page is “controlewoord.” Same column, two names, and the public-facing name was the one that reached the customer.
What runs through all three episodes is the controller’s incident response trailing the journalists’ work. Every field in the customer contact system has a name the engineers use and a name the customer sees. password_c and controlewoord are the same column. That mapping should exist in a document before a ransom note forces you to produce it. Before the journalists call, you should already know which fields were taken and which records were affected. When you do, the per-customer notification and the press statement go out together, from the same answer.
6. Pattern 4: Operational and analytical separation
Operational systems and analytical systems carry different access models. The operational system is where customer service agents work day-to-day, optimised for many concurrent users with broad read access during routine work. The analytical and archival systems are different: narrower access, audited reads, specific roles for specific purposes, and storage shaped by long-term query and retention requirements rather than by real-time interaction needs.
When ex-customer records live in the operational system, the operational system’s access model is the access model that applies to those records. The customer-service population can read them. The next session that authenticates can reach them. There is no operational reason for either of those things to be true, because the ex-customer is no longer the subject of any operational interaction. The records belong, if anywhere, in the archival layer where the access model is narrower by design.
The Odido record shows what the absence of this separation looks like. Every ex-customer row leaked through the customer contact system was a row that should have been in an archival store with audit logging, restricted role access, and a separate authentication boundary. Reach (Pattern 1) and retention (Pattern 5) both partially resolve through this separation. If the ex-customer rows are not in the operational system, the phished customer service session cannot reach them in the first place.
In practice the pattern looks like a physical and logical separation between OLTP customer contact and the historical store. Different access models on each layer. ETL out of the operational system into an ID-stripped or vault-encrypted archive once the customer relationship ends. The decision about which fields can stay in either layer at all is the combination-sensitivity question. A row containing name plus passport plus DOB plus IBAN does not have a defensible home in the operational customer contact system after the relationship ends; the same fields, separated across audited archival stores, sit very differently. I explain in Part 8 of the Modern Data Engineer series how ordinary fields combine into special-category exposure and which combinations have no defensible home in an operational store.
7. Pattern 5: Ex-customer purge architecture
Erasure is an enforced architectural process. The privacy statement describes the desired state: the system carries customer records for some bounded period after the relationship ends, after which the records are removed. The erasure architecture is the system that enforces the desired state. The gap between them is where ex-customer rows live for ten years.
The pattern requires several specific components in production: a time-based purge job that runs against the operational store, a cascade that propagates the deletion through analytical and archival stores, a validation step that confirms the records are gone where they were supposed to go, and an audit trail that records the purge happened. Each of these is an engineering deliverable with owners, tests, and SLAs. A retention SLA is a system requirement, with the testing and validation that any other system requirement carries.
The Odido record carries the statistical shape of erasure architecture that was not deployed. The privacy statement promised retention “up to a maximum of two years after the end of the contract.” FD established ex-customer records going back ten years. RTL Nieuws established at least 44,000 records from five or more years ago. Odido publicly acknowledged on 17 February 2026 that it could not explain why ex-customer data was being kept longer than the two-year promise, and it needed time to investigate.
Odido promised two years and kept ten, with no system enforcing the difference. I built the architecture that closes that gap in Part 9 of the Modern Data Engineer series: a purge job with a cascade, a completion audit, and an SLA. The Odido record is what happens when none of that exists.
8. What the five patterns share
The five patterns cover read limits, extraction observability, disclosure readiness, operational separation, and purge architecture. Together they describe one architectural posture under five different views. They tend to sit in different teams’ quarterly priorities, but in aggregate they are one decision about the platform’s posture toward the data it holds.
The phishing call that triggered the Odido breach is a separate problem with a different defence: human judgment under pressure, training, MFA fatigue policies, callback verification. The defence against the call is downstream of human factors that have their own engineering. The five patterns in this post are decisions the customer contact platform had already made years before any call landed. The patterns determined what the incident looked like once the call did its work.
A company the size of Odido will be breached. The phishing call that opened this incident will be made again, at Odido and at every other operator running a customer contact system at scale. Zero trust architecture starts from that assumption: not whether a session will be compromised, but what it can reach when it is. The five patterns are the answer to that second question.
Building these patterns into a new platform is the easy version. The hard version is the system that has been in production for years, where access roles have drifted through ten product changes, the retention job was written by someone who left in 2018, and nobody is sure what password_c actually stores until the ransom note arrives. That system is the one worth auditing, and the five patterns are what to audit against.
What was in my record was a passport number, a driver’s license number, a date of birth, an IBAN, and an address. Fourteen months after my contract ended, those fields were still inside the operational customer contact system, at the access level any phished customer service session could reach. That is the state the breach found. It was already in place on the day I switched providers, and it was still in place the morning the email arrived.
9. In practice
The five patterns compress into three disciplines that a zero trust posture runs on: data minimization, least-privilege account design, and live monitoring. Each one is small in isolation and routine to set up. The audit Section 8 describes is mostly the work of confirming these are running, in this system, against this data, today.
Data minimization is the practice of holding less. The decision points are concrete. Which fields are collected at signup. Which of those fields move from the operational store into the analytical or archival layer. Which fields are dropped at the end of the customer relationship. Which combinations of fields are allowed to coexist in any single row that an operational session can reach. Pattern 4 (separation) and Pattern 5 (purge) both run on this, and so does the read cap in Pattern 1: the smaller the row’s combined sensitivity, the less the cap has to absorb when a session is compromised.
Least-privilege account design is the practice of scoping the role before scoping the user. The customer service role does per-customer work, and its account holds exactly the authorizations for that work, no more. Bulk extraction is a separate account with a separate authorization path, separate logging, and separate approval. MFA on every account is part of the baseline; the harder work is the scope of authorizations the account holds once authenticated. The phished session in the Odido incident held more authorization than the role’s job actually required, and that gap is what the design pattern closes.
Live monitoring is the practice of watching the controls actually fire. At one of my previous clients, when my team was testing a new API ingestion, we would get a call from the SOC team to check whether the bulk-extraction pattern they had just seen was legitimate. The activity had triggered an alert that reached a human inside a window short enough for the human to intervene before the extraction completed. That is what Pattern 2 looks like operating as designed. The technical controls (volume thresholds, login-history review, anomaly detection) exist; the practice question is whether the alert reaches someone with the authority to ask the question before the extraction is over.
These three disciplines are well within reach of any data team that takes the time to set them up. The harder work is the audit of the platform that has been running for years, where the data minimization decisions were made by people no longer at the company, the role scoping has drifted through ten product changes, and the monitoring runs but does not alert. The five patterns describe what to look for during that audit; the three disciplines describe what the result looks like when the patterns are running in production.
How fast does your SOC team respond to a bulk-extraction anomaly in the logs? Is anyone actually reading those alerts? Can a standard customer service account reach a bulk export API it has no operational reason to touch? When did you last audit whether your data minimization decisions still match what’s actually in the operational store? Does your purge job have tests, an SLA, and a completion audit trail, or is it a script someone wrote in 2019 that you assume is still running? And underneath all of it: is there an audit trail that tells you who accessed which tables, APIs, and files, and when? Without that, none of the other questions have answers.
10. Postscript: 2 June 2026
This piece was written before publication. On 2 June 2026, days before I sent it out, I received a phone call from VodafoneZiggo. The agent opened with a promotional offer framed around the fact that I had been a customer of theirs more than ten years ago. I cancelled the subscription in 2015. I have had no contact with the company since.
The agent had the address I lived at in 2015, the phone number that reached me, and enough connection back to the ended subscription to use as a sales hook. Whatever else is sitting in that record was not surfaced during the call. There is no way to know from the outside.
What the Odido breach made visible at one Dutch telecom through a hostile data extraction, a routine outbound sales campaign at a different Dutch telecom made visible without any breach. The retention question that runs through Patterns 4 and 5 is broader than Odido. Across the sector, the operational customer contact system is still carrying ex-customer rows long after the published retention policy says they should be gone. The call on 2 June came more than three months after the AP and RDI formally opened their joint investigation into the Odido breach, and the architecture that placed the call to me was the architecture the AP was investigating elsewhere.
Join the Discussion
Thought this was interesting? I'd love to hear your perspective on LinkedIn.