SAFe is not Agile. It actively makes your work worse.
SAFe wraps agile vocabulary around a plan-driven framework and sells the result as scaled agility. What it actually scales is the appearance of agility, not the substance. For data teams, the damage is structural and compounding.
Large organisations adopt SAFe because real agile is genuinely threatening. It removes the roadmap, the Gantt chart, and the quarterly commitment, the artefacts management uses to feel in control. Real agile asks leadership to trust teams and respond to outcomes rather than approve plans upfront. That is a hard sell to a VP who needs something to show the board.
SAFe is the consulting industry’s answer to that discomfort. It wraps agile vocabulary around a plan-driven framework, gives management the hierarchy and governance they wanted all along, and gets sold as “scaled agility.” What it actually scales is the appearance of agility, not the substance.
To be clear about what SAFe is responding to, the coordination problems are real. Large organisations running dozens of teams face genuine challenges that agile at team level was not designed to address, including cross-team dependencies, regulatory reporting requirements, and portfolio-level visibility needs. Where SAFe goes wrong is in how it solves them. Plan-driven control treats predictability as something you manufacture through upfront commitment and governance, rather than as an outcome that emerges from teams with short feedback loops, stable backlogs, and the authority to adapt. That substitution is where the damage originates.
The uncomfortable truth is that SAFe is not just ceremonial waste. It is not a harmless pacifier that burns two days on PI planning and otherwise leaves teams alone. SAFe actively deteriorates work quality, and it does so by breaking the feedback loop that agile depends on to function.
Waterfall in a hoodie
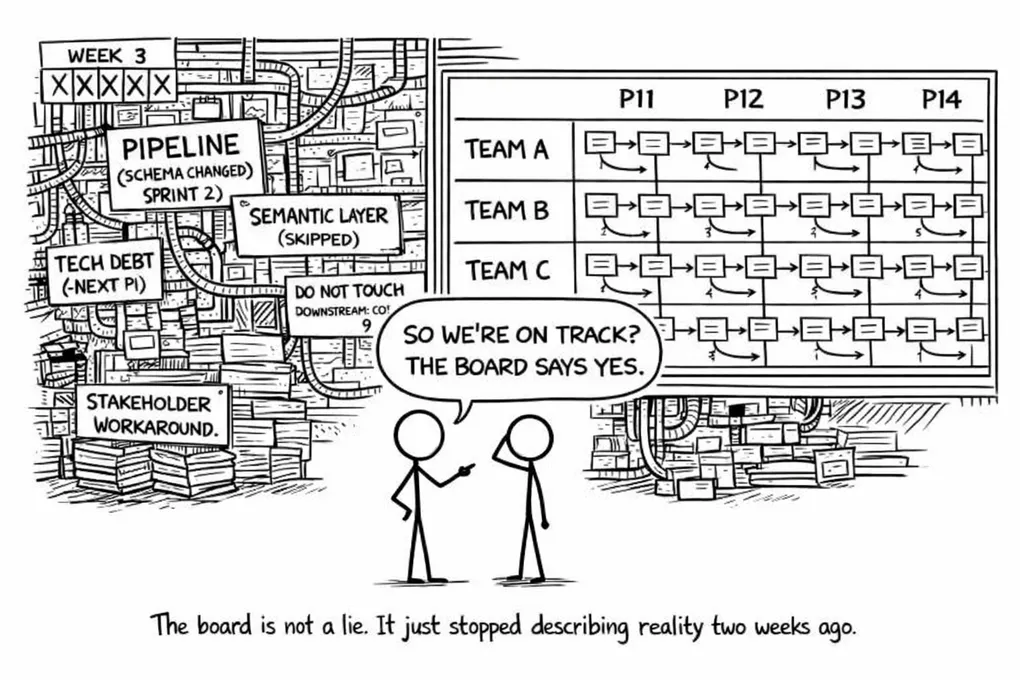
The Program Increment is a quarter, twelve weeks of committed scope negotiated at PI planning and tracked on a programme board. Whatever you call it, it is a quarterly release cycle, which is precisely what agile was invented to escape.
PI planning is elaborate enough to feel productive. Two days of sticky notes, dependency arrows, and confidence votes, after which teams leave with a board that looks like alignment and management leaves with a Gantt. Everyone feels like something happened.
Then sprint one starts.
Within two weeks the plan is fiction. Requirements were unclear. Access wasn’t provisioned. An upstream system changed. The board is wrong but nobody updates it, because the board exists for management, not for delivery. The next PI planning is the only moment that counts. In between, teams go about their actual jobs while management retains the perception of control via a Gantt that is silently, structurally outdated.
The framework was never agile to begin with.
The feedback loop is the engine, and SAFe destroys it
Despite what someone operating in a broken agile team may believe, agile’s core mechanism is not sprints, standups, or story points. Those are just the tools. Agile is to inspect and adapt, continuously. Short cycles exist specifically to surface problems before they compound, so a two-week sprint that exposes a bad architectural decision is actually a success because you found it cheaply, before it became load-bearing.
SAFe’s Inspect & Adapt event is quarterly, which means that by the time you formally surface a structural problem you have already committed to the next PI. The problem has had twelve weeks to embed itself, and fixing it is now a project rather than a sprint task.
Team retrospectives exist on paper but are structurally neutered. They operate within the Agile Release Train (ART) cadence, not above it. Learnings that require cross-team or organisational change die at the ART boundary, where nobody with budget or authority is in the room. The result is that teams discuss problems, identify solutions, and then have no mechanism to implement them. The feedback loop is broken and the learnings of the retrospectives never reach the people that can actually fix the problems. The same issues come up PI after PI, and the team is left to respond to them as best they can within the constraints of a framework that consistently punishes honesty and rewards shipping.
This is where the real damage starts.
The debt SAFe never schedules
PI commitments are often made with optimistic capacity. Reality intrudes in the form of upstream delays, unplanned work, and stakeholders who treat the PI as a binding contract and escalate when scope shifts. Something has to give, and tech debt refactoring, which has no external stakeholder, no demo, and no PI feature card anyone is waiting for, is always the first thing that gets dropped.
Sprint after sprint it gets deferred with the same implicit promise that the team will fix it next PI. Next PI arrives pre-loaded with the same roadmap pressure, and the promise expires unspent.
After three PIs you have an architecture that is genuinely fragile, not because engineers are lazy or incompetent, but because the system never created the structural space to address it. Teams are responding rationally to a framework that consistently punishes honesty and rewards shipping.
For data teams this plays out most visibly in the semantic layer. Building a proper semantic model requires uninterrupted focus and cross-team agreement on business logic, and SAFe consistently destroys both. Under PI pressure, teams scramble to deliver the visible stuff, dashboards, reports, features on the programme board. The semantic layer has no ticket, no stakeholder, no demo, so it gets skipped.
What you get instead is copy-pasted business logic, hardcoded metric definitions scattered across a dozen pipelines, horizontal lineage that nobody fully understands and everyone is afraid to touch. That is not cosmetic debt. Two reports consuming the same metric calculated two different ways will eventually disagree, and when they do, nobody knows which one is correct. Tracing it means untangling pipelines that have been in production for multiple PIs, built on top of each other by people who have since moved on.
The same pattern holds across the platform. A hacky transformation that should have been refactored becomes the foundation for three downstream models. A poorly designed ingestion layer gets depended on by five consumers. By the time the damage surfaces as a real problem, fixing it requires a rebuild, not a sprint.
The end state is the worst outcome a data team can face. Stakeholders lose trust in the platform and retreat to Excel, and at that point the team has not just accumulated debt but lost its organisational mandate entirely.
Why data teams expose this most brutally
Every team suffers under SAFe, but data teams are where the dysfunction becomes impossible to hide.
Data teams are dependency-exposed by nature. Source systems owned by other teams, other ARTs, external SaaS vendors, sometimes third parties entirely outside the organisation. You do not control your inputs, and unlike a product team that can theoretically own its slice end-to-end, a data team structurally cannot.
PI planning assumes your inputs are reasonably stable for twelve weeks. For a data team they never are. Schema changes, API deprecations, access provisioning delays, data quality incidents are not risks to log in a ROAM session but the normal operating conditions of data engineering. You are building on ground that moves. A schema change in an upstream system can break a downstream model that was closed out as done in a previous sprint, regressing delivered work without a single line of code changing on the data team’s side. A backfill retroactively invalidates metric calculations that stakeholders have already signed off and acted on. Late-arriving data shifts the numbers in dashboards that are already in production, turning a completed delivery into an open question. These are not edge cases to plan around. They happen regularly, and each one reopens commitments the framework has already marked as closed.
The result is binary and predictable. Data teams either constantly fail PI commitments and get treated as underperforming, or they learn to game the metrics, committing only to safe work, padding estimates, hiding unplanned effort behind PI features. Both outcomes are rational responses to a broken system. In SAFe, protecting the plan becomes more important than delivering value, and that inversion is where the framework crosses from inefficient to actively harmful.
What Scrum actually gets right
Scrum’s sprint commitment is about value, not a fixed plan. You commit to a goal, and how you get there is a team decision that stays adjustable within the sprint.
Scrum also expects unplanned work, and that is the point. If upstream breakage consumes 80% of a sprint and fixing it unblocks downstream analytics, that is a successful sprint because the value delivered is reliability restored. The feedback loop stays intact because two-week cycles mean problems surface fast and cheaply, retrospectives are frequent enough to actually change behaviour, and a bad decision made in sprint one is correctable by sprint three.
A framework honest enough to survive contact with reality does not need a programme board to prove it is working.
What good actually looks like
A data team running well on Scrum needs a dedicated PO who genuinely bridges business analytics priorities on one side and upstream integration dependencies on the other. This role requires technical depth and political capital simultaneously. Most organisations underfund it. Without it you get a PO who is either a business analyst with no engineering credibility or a tech lead with no stakeholder access, and either way the team eventually fails to close the gap between what the business needs and what gets built.
Reliability needs to be a first-class sprint priority, not a background concern. Breakage gets prioritised unless impact is demonstrably minimal. Pipeline reliability is a precondition for value delivery, and if the pipes are broken, nothing downstream works. This should be a standing rule, not a sprint-by-sprint negotiation. In practice it will be renegotiated every time the roadmap gets tight, and the only way to hold the line is to have the agreement explicit and pre-committed with the PO before a sprint starts, not at the moment the pressure arrives.
Because data teams deliver value with a lag (the pipeline ships now, the business value hits when analytics consumers actually use it), you need proxy metrics to avoid flying blind, tracking things like pipeline reliability, SLA adherence, consumer adoption, and data quality scores. Without them, the gap between a pipeline going to production and a stakeholder actually using the output becomes a window for programme management to flag the team as slow or unproductive. The metrics are how you make the lag visible and defensible.
For cross-team initiatives, project squads beat PI planning every time. Form a temporary squad around the outcome, not around a PI cadence. The squad dissolves when the project delivers. No programme board, no cadence lock, no quarterly theatre. Getting there requires someone with enough authority to pull people out of their existing PI commitments, and that conversation is usually harder than the work itself. It is worth having.
The kickoff for those squads is a blocker discovery session. Surface infrastructure dependencies in week one, covering firewall rules, service principal creation, network routes, data access provisioning, and environment parity. These are work items to assign immediately, not risks to log and monitor. Hit them at kickoff or you will hit them in sprint four when they are on the critical path.
Stuck in SAFe: what to do when it’s not your call
Most teams don’t choose SAFe. It arrives top-down, usually after a management offsite and a consulting engagement, and by the time the first PI planning is scheduled the decision is already made. If you are a data team inside a SAFe organisation, the framework is your operating reality whether you like it or not.
Working inside that reality without losing your actual feedback loop is the problem worth solving, and the teams that manage it do so by being deliberate about what they protect.
Keep your PI commitment loose enough to absorb reality. A PI commitment that accounts for zero unplanned work is a commitment you will break by sprint two. Reserve explicit sprint capacity for upstream disruption, not as slack but as a named budget your PO owns and defends. When stakeholders push back, tell them this is the buffer that keeps delivery consistent, and that without it the programme board will look worse, not better.
Never let the programme board reflect your real architecture decisions. The board is a management artefact. Make it credible enough to satisfy the ceremony and do your actual technical planning in the team. Your sprint goals, your refactoring priorities, your data model decisions all live in your backlog, not on a sticky note in a PI planning room.
Make tech debt visible by giving it a ticket. Invisible debt gets dropped first, every time. If a refactoring task or a semantic layer initiative has no feature card, no estimate, and no named owner it will evaporate the moment the roadmap slips. Put it on the board. Give it a stakeholder, even an internal one. It still might get deprioritised, but at that point it is an explicit decision rather than a silent deferral. That distinction matters when the conversation about platform fragility eventually happens.
Start chasing external blockers the moment you know work is coming. Firewall requests, service account creation, data access provisioning, environment parity — these have lead times measured in weeks, months, sometimes longer. If you wait until the work is in a sprint to raise them, you will be waiting for them mid-delivery when they are on the critical path and there is nothing else to pull forward. The moment a piece of work appears on the horizon, even before PI planning locks it in, is the right time to start. You are not over-planning. You are preventing a two-week provisioning queue from becoming a sprint blocker.
Release often, regardless of the PI cadence. Do not wait for PI end to ship working pipelines. If something is done in sprint two, it goes out. This decouples your actual delivery from the ceremony and keeps your feedback loop short regardless of what the programme board says. The PI demo is theatre for management. Your real release cadence is what keeps the platform healthy.
What makes this particularly important for data teams is that data feature delivery follows a natural sequence, get the data, build the model, update the visual, publish, inform the stakeholder. Under SAFe’s cadence that entire sequence becomes a single waterfall unit, and feedback only arrives once all the steps are done. Scrum’s value is breaking that sequence open earlier, getting a reaction after the model is built, before the visual is polished, before two sprints have gone into a metric definition the stakeholder never validated. The release cadence matters because that delivery sequence will otherwise run to completion in the wrong direction.
Demo to your actual stakeholders frequently, and treat it as discovery rather than progress reporting. Not the formal PI demo, but real sessions with the people consuming your data, as often as you have something to show. The purpose is not to demonstrate that you are on track but to find out whether you are building the right thing at all, because at the start of a sprint you genuinely do not know, and neither does the stakeholder.
This matters more for dashboards and data science outcomes than for pipelines. A pipeline has objective correctness criteria, and the data contract either holds or it does not. A dashboard is subjective and emergent. Stakeholders rarely know what they actually want until they see something that is wrong. A draft shown at 30% completion in sprint two costs an hour of conversation. A finished dashboard shown at PI demo that misses the point entirely costs a sprint of rework, and that rework will get deferred to the next PI.
Show rough drafts early. Show them before the layout is polished, before the colour scheme is finalised, before you have spent three sprints optimising a visualisation nobody needed. The earlier a stakeholder tells you the metric is wrong or the cut is missing, the cheaper the fix. SAFe’s quarterly cadence is particularly damaging for subjective deliverables because it gives the gap between what the stakeholder imagined and what the team built twelve uninterrupted weeks to widen. Short demo cycles are your primary defence against that.
Incorporate stakeholder feedback immediately. SAFe will frame mid-PI scope changes as a process violation. Ignore that framing for data quality issues. A stakeholder identifying an incorrect metric definition is not requesting new scope, they are reporting a bug. Treat it as one, prioritise it accordingly, and fix it in the current sprint. The programme board can survive a reprioritised story. It cannot survive a data platform stakeholders have stopped trusting.
Run real retrospectives even when they carry no weight upward. Document recurring upstream failures, dependency patterns, and architectural shortcuts, not for the ROAM session but for your own evidence base. When the conversation about platform fragility eventually reaches management, and it will, the team that has been quietly tracking the damage for three PIs is in a fundamentally different position than the team that cannot explain why delivery has slowed.
Build alliances across the ART. Other data teams are almost certainly experiencing identical dysfunction. Collective escalation carries more weight than individual complaints. Your PO is your most important relationship, and if they do not understand the dependency exposure problem before PI planning, you will spend PI planning defending commitments that were never realistic.
The cadence SAFe imposes and the cadence your platform actually needs are rarely the same thing. What the teams that stay healthy inside SAFe tend to have in common is that they treat the ceremony as a reporting layer and protect their real delivery rhythm underneath it, keeping the feedback loop intact regardless of what the programme board says about the quarter.
Closing
SAFe was designed to be sellable, not to improve delivery. It prioritises organisational comfort over honesty, and large enterprises adopt it precisely because it does not threaten hierarchy. For the consultants who sell it that is a feature, and for the teams who live inside it that is the problem.
The framework was already broken before data teams arrived. Data teams just make it impossible to ignore, because their dependencies are too real, their inputs too volatile, and their value chain too exposed to sustain the fiction of a twelve-week plan. What everyone ends up with is a framework that punishes honesty, rewards gaming, and lets technical debt and architectural shortcuts compound silently for quarters at a time, until the platform is fragile, the numbers are inconsistent, and the stakeholders have gone back to Excel.
If your planning ceremony produces a Gantt that’s obsolete by week two, you’re not doing scaled agile. You’re doing scaled pretend.
Join the Discussion
Thought this was interesting? I'd love to hear your perspective on LinkedIn.