The Modern Data Engineer Part 7: How ELT Tools Handle Hard Deletes (And What They Do Not Tell You)
The Modern Data Engineer Part 7: How ELT Tools Handle Hard Deletes (And What They Do Not Tell You)
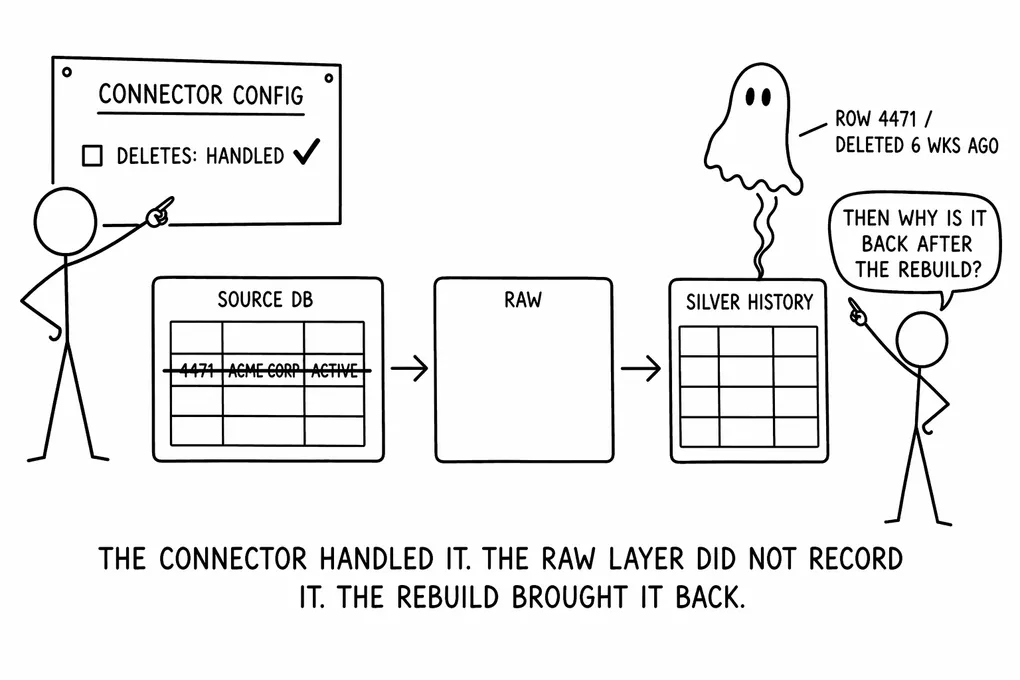
Part 6 established the structural problem: watermark-based incremental pipelines are blind to hard deletes. The fix requires two things working together: a deletion marker row in the Silver SCD Type 2 model, and a raw-layer deletion registry that a full Silver rebuild can consume independently of Silver layer state. This part looks at whether the tools engineers actually reach for have solved that problem, or quietly left it as an exercise for the reader.
A few things to say upfront about scope. The assessment here is based on product documentation, connector specifications, and design reasoning rather than a hands-on benchmark. Where I have direct production experience, I note that explicitly. For everything else, the documentation and design reasoning form the basis. Where behavior is version-specific or where I could not verify a claim against a production deployment, I say that too.
1. The evaluation framework
Before going tool by tool, it helps to state the questions clearly, because they distinguish different levels of correctness that vendor documentation tends to flatten together. “We support delete detection” can mean four different things depending on which of these questions you ask.
Q1: Does the tool detect hard deletes at all, or does it rely on the source implementing a soft delete convention?
This is the baseline question. A tool that only sees deletions because the source writes a deleted_at flag is not detecting hard deletes. It is detecting an update that happens to represent a deletion. The distinction matters when you encounter sources that do not implement the convention consistently.
Q2: Does the tool give you a genuine approximation of when the deletion occurred in the source, or just the time your pipeline noticed it was gone?
Part 6 covers this in detail. The short version: deleted_at and detected_at are not the same, and the difference affects how accurately you can represent deletion timing in your history model.
Q3: Does the tool write a durable deletion record to the raw layer, one that exists independently of Silver layer state and can drive a complete Silver rebuild? This is the rebuild fidelity question at the raw layer. A deletion signal that only propagates to Silver and is never recorded below it is not durable in the sense that matters here.
Q4: How honest is the documentation about what the connector cannot see? This one is qualitative, but it matters in practice. A connector that documents its limitations clearly is easier to reason about than one that implies coverage it does not actually provide.
2. ADF and Glue: orchestration dressed as integration
There is a widespread belief in engineering teams that using Azure Data Factory with a native connector, or AWS Glue with a JDBC source, gives you a solved integration problem. You configure the source, you get the data. What these tools actually are is orchestration runtimes that automate the extract, and the distinction matters precisely because of the problem Part 6 describes.
ADF’s copy activity has a “delete” mode, but this refers to cleaning up source or staging files after a copy operation, not detecting deleted rows in a source system. To detect row-level deletions, you run a full extract and diff it against the warehouse state. That is a snapshot comparison rather than a delete event, which means what detected the deletion was not the tool but you, by comparing two point-in-time states. I have worked with ADF and Fabric pipelines in production, and the pattern I saw repeatedly was exactly this: full snapshot with a scheduler on top, treated as a managed integration solution. ADF does have a native CDC path for database sources that connects directly to a database change feed, but it requires specific connector configuration that most deployments do not use, and the copy activity snapshot pattern is what teams typically end up with.
Glue is a Spark runtime. It provides managed infrastructure for running distributed jobs and a catalog for schema metadata, but deletion handling is whatever logic the engineer writes. There is no deletion detection in the framework itself.
Against the four questions: both tools fail Q1 on the default copy activity path. ADF has a native CDC resource for database sources, but that path requires specific connector configuration that most deployments do not use, and Glue has no deletion detection in the framework itself. Q2 is not applicable in either case, since the “timestamp” is the batch run time rather than anything from the source. Neither produces a raw-layer deletion record, so Q3 is no. On Q4, the ADF documentation is reasonably clear that the copy activity is a data movement tool, but the gap between “native connector” and “managed integration” is something that has to be discovered rather than stated plainly.
This may sound like criticism of ADF or Glue, but it is not. They are doing what they are designed to do. The issue is the assumption that attaching a native connector to an orchestration runtime produces a robust integration layer, when what it actually produces is an automated full extract that needs deletion handling engineered on top of it.
3. Singer and Meltano: the long tail
Singer is a specification for building data connectors. The spec defines how a tap extracts data from a source and how a target writes it to a destination, but it says nothing about how delete handling should work. Whether a given tap detects deletions, what mechanism it uses, and what it writes are entirely up to whoever wrote the tap.
In practice this means the quality and behavior vary enormously across the connector ecosystem. Most taps do not document their delete behavior clearly, and the only way to know what a tap does with a deleted row is to read its source code. Meltano inherits this directly. It is an execution and management layer built around Singer, so the deletion story for any given source is whatever the underlying tap implements. The Singer spec has no concept of a raw-layer deletion registry, and the tap ecosystem was not designed with rebuild fidelity as a requirement.
If you are running Singer-based connectors, the practical implication is that you cannot assume deletion handling is present without verifying it against the tap source. Q3 fails by design at the spec level.
4. Fivetran
Fivetran has the most developed deletion story among the managed SaaS connectors, and the documentation is genuinely more complete than what you typically find elsewhere. That said, there are a few distinctions worth understanding precisely rather than relying on platform-level claims.
Delete detection exists and is documented, but it varies by connector. Not every Fivetran connector uses the same mechanism, and for API-based sources where Fivetran does not have access to the underlying database, the detection is typically a snapshot diff rather than an event-based approach. The _fivetran_deleted flag is written to the destination when a row is detected as deleted, and this flag does persist in the destination table. If you query the raw destination table directly, the deleted rows are still there and marked. That is genuinely useful, and it is more than most tools give you by default.
The question is whether this constitutes a durable raw-layer deletion registry in the sense Part 6 describes. In standard mode, Fivetran writes _fivetran_deleted = true to the row in the destination table. This is a row-level marker, not a separate deletion event record. In History Mode, Fivetran maintains full row history by appending a new version of the row for every state change rather than updating in place, which means deleted rows appear as versioned records with deletion timestamps. History Mode gives you something closer to a deletion registry, but it is embedded in the destination table structure rather than being a separate artifact, and its rebuild behavior depends on whether Fivetran re-syncs that deletion history or only re-syncs current source state when you reload a connector. What History Mode preserves is a sequence of row states, and a deletion becomes visible only when the latest state for a given key carries a deletion timestamp and no subsequent state follows it, which means downstream consumers and replay logic need to infer the deletion rather than consuming it as a discrete event, with the idempotency implications that inference carries.
On Q1: deletion is detected, but for most SaaS API sources this is soft-delete-equivalent behavior via snapshot diff, not WAL-based event detection. If the source soft-deletes internally and Fivetran sees the flag, it is detecting an update. If the source hard-deletes and Fivetran catches it via key comparison, the detection is there but the timestamp (Q2) reflects detected_at rather than deleted_at. On Q3: the deleted rows are preserved in the destination, which is better than nothing, but whether this qualifies as a durable deletion registry for rebuild purposes depends on the mode and whether Fivetran’s resync behavior includes deletion history. On Q4: the platform documentation is more honest about connector-level variation than most vendors, though you still need to read at the individual connector level rather than relying on the platform overview.
The strongest managed SaaS story on deletes in this comparison, but “covered” often means soft delete detection rather than event-based deletion, and rebuild fidelity still requires connector-specific verification.
5. Airbyte
Airbyte has CDC support, and this is meaningfully different from snapshot-based delete detection. But CDC support is not platform-wide. It exists for a subset of connectors, primarily those connecting to databases where WAL access is possible. For API-based sources, Airbyte typically operates the same way as other connectors in this list: full or incremental extract with snapshot comparison.
The _ab_cdc_deleted_at field is written when a CDC-enabled connector processes a deletion event. Where CDC is active, this field contains a timestamp from the replication stream, which is closer to the WAL commit time than to a detected_at. Where CDC is not active, the field is either absent or null, depending on the connector. The distinction matters because a column that is sometimes populated and sometimes not creates a consumption pattern that is easy to misread.
On Q3: for connectors where CDC is active, deletion events are written to the raw tables in the destination, and those records include a _ab_cdc_deleted_at timestamp. This is genuinely a raw-layer deletion artifact.
The community versus certified connector split also matters here. Certified connectors are maintained by the Airbyte team and have better-documented behavior. Community connectors vary significantly. Before relying on a connector’s deletion handling for any source, verifying at the individual connector level is still required, and the documentation quality for community connectors is not reliable enough to skip that step.
Better than Singer on documentation, and CDC support is a genuine architectural advantage for database sources where WAL access is available. But the verification requirement at the connector level does not go away, and the raw-layer rebuild path requires deliberate design rather than being provided out of the box.
On the four questions for CDC-enabled connectors: Q1 yes, actual deletion events. Q2 yes for CDC sources, the timestamp is from the replication stream. Q3 yes, deletion records exist in raw tables. Q4 the documentation distinguishes CDC and non-CDC connectors, though the gap between a certified connector and a community connector is not always visible at the source selection stage.
6. dlt: code-first, explicit by design
dlt (data load tool) takes a different approach from the managed connectors: it gives you a framework for building pipelines in Python, with first-class support for incremental loading and state management, but does not abstract away the decisions you need to make about what the pipeline can and cannot see.
This has a real advantage. With dlt, you know exactly what your pipeline is doing because you wrote it. If you have not implemented deletion detection, you know that too. The framework is not going to silently handle it for you and equally is not going to imply that it did. For teams that are comfortable with code and want full control over the ingestion contract, this explicitness is genuinely valuable.
The cost is implementation work. dlt provides the scaffolding for incremental loading, state management, and schema evolution, but the deletion detection logic is yours to write. Snapshot diff against a warehouse state, soft delete convention handling, or a custom mechanism for sources that offer one: all of these are implementable within the dlt model and fit naturally in its design. What dlt does not provide is a raw-layer deletion registry as a framework feature. dlt does provide a hard_delete hint and an SCD2 merge strategy for explicit deletion handling, though these are opt-in rather than the default, and using them still requires you to understand the source’s delete behavior. The framework gives you the mechanism rather than leaving you to build it from scratch. If you write deletion records to the raw layer, it is because you designed and implemented that behavior in your pipeline code.
The rebuild fidelity argument from Part 6 applies directly here. If your dlt pipeline does not write a deletion record to the raw layer when it detects a deletion, then dropping and rebuilding the Silver layer from dlt’s raw tables will reproduce the ghost row. The raw tables contain what arrived from the source, and a hard delete produces nothing in those tables unless you put it there. dlt’s code-first design means this is fixable, and the fix is relatively natural in the framework, but it requires you to write it.
On the four questions: Q1 is no by default, but opt-in via the hard_delete hint or SCD2 merge strategy. Q2 works the same way: the timestamp goes where you put it in your code. Q3 is no by default and yes if explicitly implemented using the framework’s deletion handling features. Q4 is the strongest score in this comparison: dlt’s documentation is honest about what the framework provides and what it does not, which is the most you can ask for from a tool that is explicitly code-first.
7. Debezium: the reference implementation
Debezium occupies a different position in this comparison because it is the only tool here that produces actual deletion events rather than detecting deletions by comparing snapshots. One could say, it is purposely built this way. The distinction is architectural rather than just a quality difference.
Debezium reads from the database write-ahead log, the ordered record of every write before it reaches storage, and translates those records into structured events that are published to Kafka. When a row is deleted in the source, the WAL contains a delete record with the row’s primary key and the transaction commit timestamp. Debezium translates that into a deletion event with the same information. The timestamp in that event is the WAL commit time: the moment the transaction was written to the log, not the moment the downstream consumer processed the event and not the moment your ingestion pipeline ran. For SCD Type 2 history models, this gives you the closest available approximation of when the deletion actually happened, with precision to the WAL commit timestamp (sub-second in PostgreSQL, seconds-level in MySQL) rather than to the next pipeline batch window.
These deletion events land in Kafka as first-class records. If your ingestion design lands those Kafka events to the raw layer as part of the normal pipeline flow, you get a genuine raw-layer deletion registry: a durable, ordered record of every deletion event with its primary key and commit timestamp. A Silver rebuild that consumes that raw layer can process the deletion events, close the appropriate SCD records, and write deletion marker rows in exactly the same way the original pipeline did. This is the only tool in this comparison where Q3 can be answered yes without additional custom engineering on top of what the tool provides by default.
A terminology note carried over from Part 6: in Kafka literature, “tombstone” refers to a null-value record used for log compaction in compacted topics. The deletion marker row concept described in Part 6 is the SCD history pattern, not the Kafka construct. Where both come up in the same ingestion design they should be distinguished clearly to avoid confusion.
On the four questions: Q1 yes, WAL-level deletion events. Q2 yes, WAL commit timestamp gives you the closest available approximation of deleted_at. Q3 yes, if deletion events are landed to the raw layer as part of the pipeline design. Q4 the documentation is accurate about what Debezium provides and what is required of the surrounding infrastructure.
The constraint that limits Debezium’s applicability is access. WAL replication requires direct database connectivity and replication permissions. For managed SaaS sources where you connect via API rather than to the underlying database, WAL access is not available. The tools that can access the WAL and the sources that matter most in SaaS-heavy environments are almost entirely separate populations, which explains why Debezium is the reference implementation and not the standard one.
8. DBT snapshots: what invalidate_hard_deletes does and where it stops
DBT is a transformation framework, not an ingestion connector, and unlike every other tool in this comparison it has no connection to source systems. It operates entirely on data that is already in the warehouse. It is included here because engineers frequently reach for invalidate_hard_deletes as a way to handle deletions in their snapshot models, and in some team contexts that feature gets treated as a complete solution to the hard delete problem, when the connector-level question of whether a deletion even reaches the warehouse has not been answered yet.
DBT snapshots do something useful and specific: they track row-level changes over time in the warehouse by comparing the current source state to the previously snapshotted state, and they write the history as SCD Type 2 records. For sources where you have a reliable updated_at column and changes are the primary concern, snapshots handle a significant amount of the implementation work you would otherwise write by hand.
The invalidate_hard_deletes configuration option exists to handle rows that disappear from the source. When enabled, DBT compares the keys in the current source query against the set of open snapshot records, identifies rows in the snapshot that are no longer present in the source, and closes them by setting dbt_valid_to to the current timestamp. This is correct behavior for what it is. The closing logic runs, the ghost row is closed, and downstream models that query for open records stop returning the deleted entity.
The structural constraint is important to understand and is not a criticism of DBT. DBT operates on data that is already in the warehouse. It has no connection to the source system beyond what the warehouse can see through the snapshot’s source query. It has no access to the WAL, no ability to receive deletion events, and no mechanism for distinguishing a row that was deleted from a row that temporarily dropped out of the source query for some other reason. invalidate_hard_deletes is a snapshot diff, and it shares the detection limitations of any snapshot diff: the timestamp it writes to dbt_valid_to is the time the snapshot ran, not the time the deletion happened in the source. The precision loss described in Part 6 applies.
The rebuild fidelity problem is where DBT’s position in the stack becomes a hard constraint. DBT has no raw layer. When invalidate_hard_deletes closes a snapshot record, it writes nothing to any layer below the Silver model. If the snapshot table is dropped and rebuilt from scratch, the rebuild runs the snapshot source query against current source state, and the deleted row is simply absent with no signal that it was ever open and no artifact in the raw layer that a rebuild could consume to reproduce the closed record and the deletion marker row that Part 6 describes.
This is not fixable within DBT’s design. The fix is upstream in the ingestion layer, before the snapshot runs: a raw-layer deletion registry that encodes the deletion as a durable fact the snapshot logic can consume on rebuild. The transformation layer cannot write to the raw layer. That is the boundary the architecture enforces, and it is the right boundary. But it means treating invalidate_hard_deletes: true as a complete solution to the hard delete problem is a mistake, because it handles the operational case while leaving the rebuild path broken.
A version note: invalidate_hard_deletes was deprecated in DBT Core 1.9 in favor of hard_deletes: 'invalidate' as a snapshot configuration key. The behavior is equivalent, but if you are working from documentation predating 1.9 the syntax will differ.
On the four questions: Q1 yes, snapshot diff detects disappearing rows. Q2 no, the timestamp is detected_at rather than deleted_at. Q3 no, DBT writes nothing to the raw layer. Q4 the DBT documentation describes what invalidate_hard_deletes does accurately, though the rebuild limitation requires reading the architecture carefully to understand rather than being called out explicitly.
9. Synthesis
| Tool | How it handles deletes | Deletion record in raw layer |
|---|---|---|
| ADF / Glue | Snapshot diff or custom logic | No |
| Singer / Meltano | Tap-dependent | No |
| Fivetran | Snapshot diff; row flag in destination | Connector-specific |
| Airbyte | CDC (database sources) or snapshot diff | Connector-specific |
| dlt | Opt-in via hard_delete hint | No — opt-in only |
| Debezium | WAL events | Yes |
| DBT snapshots | Snapshot diff against warehouse state | No |
The four questions above form a practical checklist you can apply to any tool or connector before assuming it has this covered. Working through them, the pattern that emerges is consistent enough to be worth stating plainly.
When a vendor says a connector has “CDC support” or “delete detection,” what you need to verify is the detection mechanism (WAL event vs. snapshot diff vs. soft delete flag), what timestamp the deletion record carries, and whether the deletion is written to a durable raw-layer artifact that exists independently of downstream state. Most vendor documentation does not address all three of these at the connector level, and the platform-level claims are typically written at the first question rather than the last.
The rebuild fidelity test from Part 6 stated plainly: does your raw layer contain a durable deletion registry (a record of every detected deletion with its primary key and timestamp) that exists independently of Silver layer state and can drive a complete Silver rebuild? For most tools and most source types, the answer is no by default, and the documentation will not tell you that.
What a reasonable engineering approach looks like depends on the source type.
For a relational database with WAL access available, Debezium is the appropriate tool. It is the only option in this comparison that gives you actual deletion events, WAL commit timestamps, and a natural path to a durable raw-layer deletion registry through Kafka topic retention and raw-layer landing.
For a managed SaaS API source, Fivetran in History Mode or Airbyte with a CDC-enabled connector where available are the strongest starting points. In both cases, connector-level verification is required rather than platform-level trust. The detection mechanism for API sources is almost always snapshot-based, which means the timestamp limitation described in Part 6 applies. If the tool does not produce a raw-layer deletion registry by default, the right architectural response is to design one explicitly: a technical table in the raw layer that records the primary key and detected_at for every deletion the pipeline catches.
For a file-based source or an API source without any CDC capability, you are working with snapshot diff only. Accept that valid_to in the SCD model reflects detected_at rather than deleted_at, document that limitation in the model, and design the deletion registry explicitly. The precision loss is real but it is not a reason to skip the raw-layer artifact. The rebuild fidelity argument holds regardless of what the timestamp represents.
The uncomfortable conclusion that runs through all of this is that for most source types, the tool handles the transport and the extraction. The deletion contract (whether deletions are detected, what timestamp they carry, and whether they are durable enough to survive a rebuild) is still your responsibility, even when the tool appears to have solved it.
That pattern is part of why I gravitate toward building ingestion components rather than relying on managed connectors for sources where deletion fidelity matters. A custom pipeline written against a source API or database can encode the deletion detection behavior explicitly, specifying what to check, what to write to the raw layer, and what the downstream contract looks like. The behavior does not vary by connector version, platform tier, or which engineer originally configured the source, and it does not require per-connector documentation archaeology to reason about when something goes wrong. The tradeoff is maintenance ownership, which is not trivial, and for sources where managed tooling handles the deletion contract reliably that ownership is not worth taking on. For sources where it does not, the explicitness of a custom implementation is usually easier to reason about than tracking connector-level behavior across tool upgrades.
10. Closing
Parts 6 and 7 together describe a problem that spans two layers. Part 6 established what the problem is and what a complete structural solution looks like: deletion marker rows in Silver and a raw-layer deletion registry that makes the Silver model rebuildable. This part looked at whether the tools engineers reach for in practice provide that solution, and found that most of them leave the rebuild fidelity problem to you, with varying degrees of honesty about that fact. Debezium is the exception, and its access constraints explain why it remains the exception rather than becoming the standard. The underlying difference is that snapshot-based tools reconstruct the last known state of a row, while WAL-based systems reconstruct the ordered sequence of events that produced it, and only the event sequence gives you a replay path that is guaranteed to arrive at the correct history regardless of when the replay runs.
One related topic that this series has deferred and will continue to defer: GDPR erasure. A forget-me deletion is a meaningfully different kind of event from the pipeline-rebuild deletions this post covers. It carries legal obligations that extend across the entire warehouse, including history tables that were designed to be immutable, and it requires its own deletion registry, downstream erasure jobs, and careful decisions about what anonymisation means for a conformed entity that other models depend on. A deletion registry designed for pipeline rebuild and one designed for GDPR compliance are not the same artifact and should not be conflated. That topic deserves its own treatment.
Join the Discussion
Thought this was interesting? I'd love to hear your perspective on LinkedIn.